Flash Attention
Understanding FlashAttention
Transformer models spend a significant amount of time computing the attention operation. While GPUs are capable of performing billions of computations per second, the real bottleneck is often memory access, not computation.
FlashAttention is an optimized attention algorithm that minimizes memory movement between GPU memory and on-chip memory, making attention significantly faster while producing exactly the same output as standard attention.
Standard Attention
Given the Query (Q), Key (K), and Value (V) matrices,
attention is computed as:
The first step computes the attention score matrix , whose size is
For long sequences, this matrix becomes enormous and consumes a large amount of GPU memory.
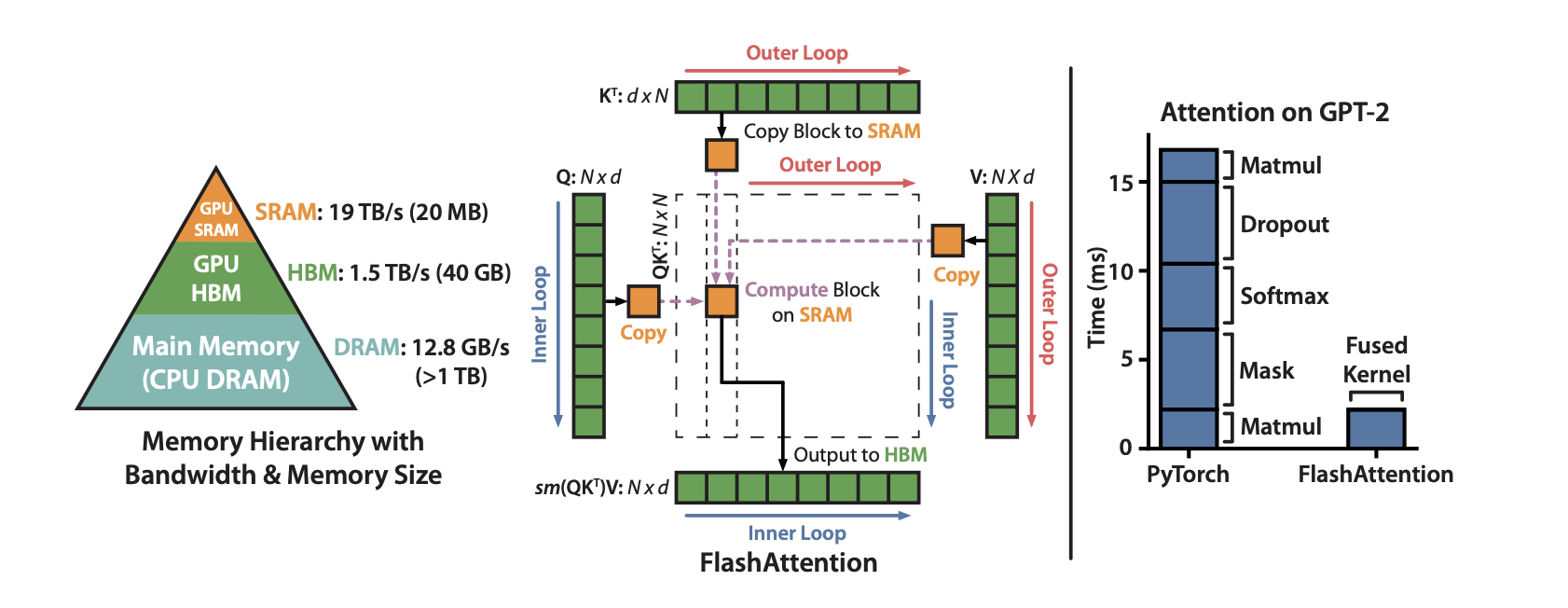
The Memory Bottleneck
GPUs contain two important types of memory:
- HBM (High Bandwidth Memory / GPU DRAM) – Large capacity but relatively slow.
- SRAM (Shared Memory / Registers) – Very small but extremely fast.
Although the GPU can perform matrix multiplications quickly, repeatedly moving data between HBM and SRAM becomes the dominant cost.
In standard attention:
- Q, K, and V are stored in HBM.
- The large attention matrix is created and written back to HBM.
- The attention matrix is read again for the softmax computation.
- The result is read once more for multiplication with V.
As sequence length increases, memory traffic grows rapidly and becomes the performance bottleneck.
How FlashAttention Works
Instead of computing the entire attention matrix at once, FlashAttention divides Q, K, and V into small tiles (blocks) that fit inside SRAM.
Each tile is processed independently, allowing almost all computations to occur in fast on-chip memory.
The algorithm performs the following steps:
- Load a block of Q into SRAM.
- Load a block of K into SRAM.
- Compute the partial attention scores.
- Update the running softmax statistics.
- Load the corresponding block of V.
- Accumulate the output.
- Discard the tile and process the next one.
Because only one tile is processed at a time, the full N × N attention matrix is never materialized in HBM.
This dramatically reduces memory traffic while producing exactly the same attention output.
FlashAttention Tiling
Evolution of FlashAttention
| Feature | FlashAttention v1 | FlashAttention v2 | FlashAttention v3 |
|---|---|---|---|
| Main optimization | Memory access | Memory + GPU parallelism | Hardware pipeline optimization |
| Tiling | ✅ | ✅ | ✅ |
| Online softmax | ✅ | ✅ | ✅ |
| Improved GPU scheduling | ❌ | ✅ | ✅ |
| Asynchronous execution | ❌ | Limited | ✅ |
| Hopper-specific optimizations | ❌ | ❌ | ✅ |
| Relative speed | Fast | ~2× faster than v1 | Fastest on Hopper GPUs |
FlashAttention v1
The first version introduced tiling and online softmax, eliminating the need to store the full attention matrix.
FlashAttention v2
Version 2 improves GPU workload distribution and parallelism, leading to much better utilization of Streaming Multiprocessors (SMs) and roughly doubling performance compared to v1.
FlashAttention v3
Designed specifically for NVIDIA Hopper GPUs, FlashAttention v3 leverages hardware features such as asynchronous memory transfers and optimized Tensor Core pipelines for maximum throughput.
Why Online Softmax Is Needed
In standard attention, softmax is computed as:
The denominator requires the sum of the exponentials of every score in a row.
Normally, the model first computes the entire attention matrix:
and then calculates:
This requires all attention scores to exist in memory simultaneously.
FlashAttention cannot do this because it only processes one tile at a time.
The Challenge
Suppose one row of attention scores is:
FlashAttention processes them in tiles:
After processing the first tile, the algorithm has not yet seen the remaining values.
Therefore, it cannot directly compute:
A different strategy is required.
Online Softmax
Online softmax computes the softmax incrementally.
Instead of storing every attention score, it maintains only two running statistics:
Initially:
For every new tile, FlashAttention:
- Finds the maximum score in the tile.
- Updates the global maximum.
- Rescales the previous exponential sum if the maximum changes.
- Adds the exponentials from the current tile.
After processing every tile, the algorithm has the exact softmax denominator without ever storing the entire attention matrix.
Example
Suppose the attention scores are:
Tile 1
Tile . The maximum is
and the running sum is
Tile 2
Tile . The new maximum becomes
The previous sum must be rescaled to the new maximum:
Now add the new tile:
Tile 3
Tile . The maximum remains
Update the running sum:
The final denominator is
which is mathematically identical to
even though all five scores were never stored simultaneously.
Why Online Softmax Matters
Without online softmax:
- The full N × N attention matrix must be stored.
- Memory complexity is O(N²).
With online softmax:
- Scores are processed one tile at a time.
- Only the running maximum and running exponential sum are stored.
- Memory movement between HBM and SRAM is greatly reduced.
- The output is exactly the same as standard softmax.
Online softmax is one of the key innovations that enables FlashAttention to achieve high performance while remaining mathematically exact.
Conclusion
FlashAttention does not change the attention algorithm—it changes how it is executed on GPU hardware.
By processing attention in tiles and computing softmax incrementally, it avoids materializing the massive attention matrix and dramatically reduces memory traffic between HBM and SRAM.
As a result, FlashAttention enables faster training and inference, lower memory consumption, and better scalability for modern large language models.