Grouped-Query Attention
One of the biggest challenges in serving Large Language Models is not raw compute — it is memory consumption during inference. Grouped-Query Attention (GQA) is the small architectural change that quietly made long-context, high-throughput inference affordable.
The KV Cache Problem
Unlike training, autoregressive generation reuses every previously computed Key (K) and Value (V) tensor when predicting the next token. To avoid recomputing them at every step, they are stored in a KV cache.
That cache grows with every layer, every head, and every token. Consider a fairly ordinary model:
- 32 attention heads
- Head dimension = 128
- Context length = 8,192 tokens
- 40 transformer layers
The KV cache alone needs roughly 1.3 GB per sequence in FP16 — before you account for batching. Double the batch size or the context length and it doubles again. As context windows grew from 4K to 128K tokens and beyond, the KV cache became one of the largest consumers of GPU memory, often the hard limit on how many requests a server can handle at once.
GQA was introduced to shrink this cache without meaningfully hurting quality.
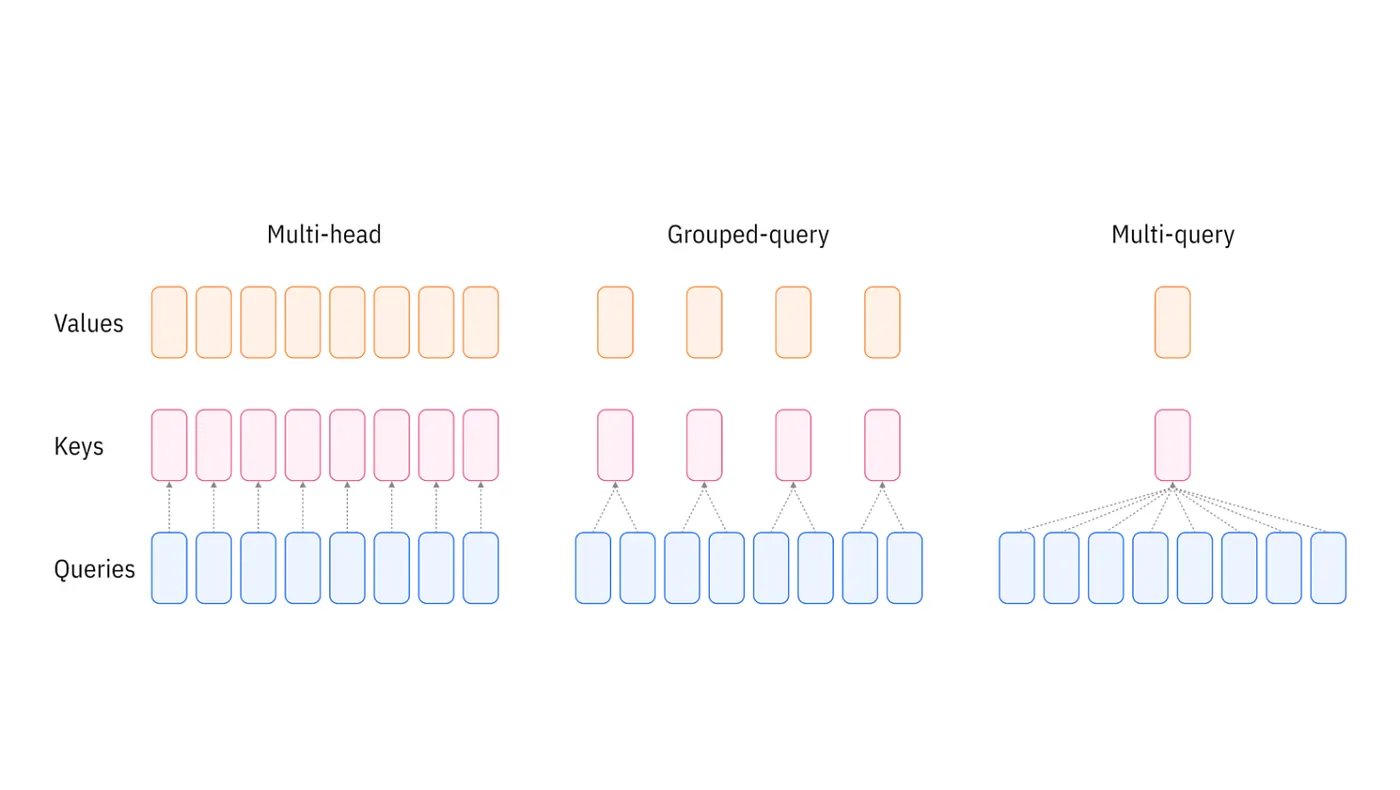
Multi-Head Attention
The original Transformer paper, Attention Is All You Need, introduced Multi-Head Attention (MHA). Instead of learning a single attention function, the model learns several in parallel, and each head owns its own Query, Key, and Value projection.
Each head attends to the sequence independently, and the outputs are concatenated and projected back to the model dimension.
How It Works
The computation is five steps:
- Project the input into Query, Key, and Value matrices.
- Split each projection into
num_headsseparate heads. - Attend — every head independently computes
- Concatenate the per-head outputs.
- Project the result through a final linear layer.
Why Multiple Heads?
With and heads, each head works in a smaller subspace of
dimensions. Different heads tend to specialize — some track local syntax, others grammar, entity relationships, or long-range dependencies. Several small attention spaces are usually more expressive than one large one.
Crucially, splitting into more heads does not add parameters. Across all heads the Query projection costs
so the cost stays regardless of head count.
Show Multi-Head Attention implementation
import torch
import torch.nn as nn
import math
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
"""
Args:
d_model: Dimension of the model (e.g., 512, 768, etc.)
num_heads: Number of attention heads (e.g., 8, 12, etc.)
"""
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.head_dim = d_model // num_heads # Dimension per head
# Linear projections for Q, K, V
# Each projects from d_model to d_model (which will be split into heads)
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
# Output projection
self.out_proj = nn.Linear(d_model, d_model)
# Scaling factor for dot products
self.scale = math.sqrt(self.head_dim)
def forward(self, x, mask=None):
"""
Args:
x: Input tensor of shape (batch_size, seq_len, d_model)
mask: Optional mask tensor
Returns:
Output tensor of shape (batch_size, seq_len, d_model)
"""
batch_size, seq_len, _ = x.shape
# Apply linear projections
Q = self.q_proj(x) # (batch_size, seq_len, d_model)
K = self.k_proj(x) # (batch_size, seq_len, d_model)
V = self.v_proj(x) # (batch_size, seq_len, d_model)
# Reshape and transpose for multi-head attention
# Split d_model into num_heads * head_dim
Q = Q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
K = K.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
V = V.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# Shape: (batch_size, num_heads, seq_len, head_dim)
# Compute attention scores
scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale
# Shape: (batch_size, num_heads, seq_len, seq_len)
# Apply mask if provided
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# Apply softmax to get attention weights
attn_weights = torch.softmax(scores, dim=-1)
# Apply attention weights to values
attn_output = torch.matmul(attn_weights, V)
# Shape: (batch_size, num_heads, seq_len, head_dim)
# Concatenate heads
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, seq_len, self.d_model)
# Apply output projection
output = self.out_proj(attn_output)
return output
The Problem with Multi-Head Attention
MHA performs beautifully, but every head keeps its own Key and Value. For a 32-head model the cache stores 32 Keys and 32 Values at every layer, for every token. That is exactly the term that explodes for long contexts.
The natural question: do we really need 32 distinct Keys and Values, or can heads share?
Multi-Query Attention
Multi-Query Attention (MQA) takes sharing to the extreme: keep all 32 Query heads, but give them a single shared Key and a single shared Value.
The KV cache shrinks by 32×. But collapsing all Keys and Values into one pair throws away a lot of representational capacity, and models trained this way tend to lose quality and become less stable.
Grouped-Query Attention
GQA is the middle ground. Instead of one KV pair per head (MHA) or one KV pair total (MQA), groups of Query heads share a KV pair.
With 32 Query heads and 8 KV heads, every 4 Query heads share one Key and one Value:
This is where the name comes from: the queries are grouped around a shared Key/Value.
Why Does Sharing Still Work?
Even though four heads share a Key and Value, their Query projections are still different. Head 0 and Head 1 in the same group compute
Because , the two heads produce different attention distributions over the same Keys and Values. Most of the per-head specialization lives in the Query, so sharing K and V costs surprisingly little quality.
Show Grouped-Query Attention implementation
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, num_query_heads, num_kv_heads):
"""
Args:
d_model: Dimension of the model (e.g., 512, 768, etc.)
num_query_heads: Number of query heads (e.g., 32)
num_kv_heads: Number of key-value heads (e.g., 8)
Must divide num_query_heads evenly
"""
super().__init__()
assert d_model % num_query_heads == 0, "d_model must be divisible by num_query_heads"
assert num_query_heads % num_kv_heads == 0, "num_query_heads must be divisible by num_kv_heads"
self.d_model = d_model
self.num_query_heads = num_query_heads
self.num_kv_heads = num_kv_heads
self.num_queries_per_kv = num_query_heads // num_kv_heads
self.head_dim = d_model // num_query_heads
# Query projection: still projects to full d_model
self.q_proj = nn.Linear(d_model, d_model)
# Key and Value projections: project to fewer dimensions
# Only num_kv_heads worth of dimensions instead of num_query_heads
self.kv_dim = num_kv_heads * self.head_dim
self.k_proj = nn.Linear(d_model, self.kv_dim)
self.v_proj = nn.Linear(d_model, self.kv_dim)
# Output projection
self.out_proj = nn.Linear(d_model, d_model)
# Scaling factor
self.scale = math.sqrt(self.head_dim)
def forward(self, x, mask=None):
"""
Args:
x: Input tensor of shape (batch_size, seq_len, d_model)
mask: Optional mask tensor
Returns:
Output tensor of shape (batch_size, seq_len, d_model)
"""
batch_size, seq_len, _ = x.shape
# Apply linear projections
Q = self.q_proj(x) # (batch_size, seq_len, d_model)
K = self.k_proj(x) # (batch_size, seq_len, kv_dim) <- Smaller!
V = self.v_proj(x) # (batch_size, seq_len, kv_dim) <- Smaller!
# Reshape queries for multiple heads
Q = Q.view(batch_size, seq_len, self.num_query_heads, self.head_dim).transpose(1, 2)
# Shape: (batch_size, num_query_heads, seq_len, head_dim)
# Reshape keys and values for fewer heads
K = K.view(batch_size, seq_len, self.num_kv_heads, self.head_dim).transpose(1, 2)
V = V.view(batch_size, seq_len, self.num_kv_heads, self.head_dim).transpose(1, 2)
# Shape: (batch_size, num_kv_heads, seq_len, head_dim)
# Repeat K and V to match the number of query heads
# Each KV head is shared by num_queries_per_kv query heads
K = K.repeat_interleave(self.num_queries_per_kv, dim=1)
V = V.repeat_interleave(self.num_queries_per_kv, dim=1)
# Shape: (batch_size, num_query_heads, seq_len, head_dim)
# Now the rest is identical to Multi-Head Attention
scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attn_weights = torch.softmax(scores, dim=-1)
attn_output = torch.matmul(attn_weights, V)
# Concatenate heads
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, seq_len, self.d_model)
# Apply output projection
output = self.out_proj(attn_output)
return output
The only structural differences from MHA are the smaller k_proj / v_proj outputs and the repeat_interleave that broadcasts each KV head back across its group. Note that MHA and MQA are just the endpoints of GQA: num_kv_heads == num_query_heads is MHA, and num_kv_heads == 1 is MQA.
Experiment: Measuring the Savings
The benchmark below runs both modules on the same input and reports shapes and KV-cache sizes.
- batch size = 2
- sequence length = 10
- model dimension = 512
- 32 Query heads, 8 KV heads
Show complete benchmark code
import torch
import torch.nn as nn
import math
# Set random seed for reproducibility
torch.manual_seed(42)
# Configuration
batch_size = 2
seq_len = 10
d_model = 512
num_query_heads = 32
num_kv_heads = 8
# Create random input
x = torch.randn(batch_size, seq_len, d_model)
print("=" * 70)
print("INPUT CONFIGURATION")
print("=" * 70)
print(f"Input shape: {x.shape}")
print(f" - Batch size: {batch_size}")
print(f" - Sequence length: {seq_len}")
print(f" - Model dimension (d_model): {d_model}")
print()
# ============================================================================
# Multi-Head Attention Example
# ============================================================================
print("=" * 70)
print("MULTI-HEAD ATTENTION")
print("=" * 70)
mha = MultiHeadAttention(d_model=d_model, num_heads=num_query_heads)
mha_output = mha(x)
print(f"Number of heads: {mha.num_heads}")
print(f"Head dimension: {mha.head_dim}")
print()
print("Weight matrices:")
print(f" Q projection: {d_model} → {d_model}")
print(f" K projection: {d_model} → {d_model}")
print(f" V projection: {d_model} → {d_model}")
print()
print("After projection and reshaping:")
print(f" Q shape: (batch={batch_size}, heads={num_query_heads}, seq={seq_len}, head_dim={mha.head_dim})")
print(f" K shape: (batch={batch_size}, heads={num_query_heads}, seq={seq_len}, head_dim={mha.head_dim})")
print(f" V shape: (batch={batch_size}, heads={num_query_heads}, seq={seq_len}, head_dim={mha.head_dim})")
print()
print(f"Output shape: {mha_output.shape}")
print()
# Calculate KV cache size for MHA
kv_cache_mha = num_query_heads * mha.head_dim * seq_len * 2 # *2 for K and V
print(f"KV cache size per sample: {kv_cache_mha:,} elements")
print()
# ============================================================================
# Grouped-Query Attention Example
# ============================================================================
print("=" * 70)
print("GROUPED-QUERY ATTENTION")
print("=" * 70)
gqa = GroupedQueryAttention(d_model=d_model, num_query_heads=num_query_heads, num_kv_heads=num_kv_heads)
gqa_output = gqa(x)
print(f"Number of query heads: {gqa.num_query_heads}")
print(f"Number of KV heads: {gqa.num_kv_heads}")
print(f"Queries per KV head: {gqa.num_queries_per_kv}")
print(f"Head dimension: {gqa.head_dim}")
print()
print("Weight matrices:")
print(f" Q projection: {d_model} → {d_model}")
print(f" K projection: {d_model} → {gqa.kv_dim} (smaller!)")
print(f" V projection: {d_model} → {gqa.kv_dim} (smaller!)")
print()
print("After projection and reshaping:")
print(f" Q shape: (batch={batch_size}, heads={num_query_heads}, seq={seq_len}, head_dim={gqa.head_dim})")
print(f" K shape: (batch={batch_size}, heads={num_kv_heads}, seq={seq_len}, head_dim={gqa.head_dim}) [before repeat]")
print(f" V shape: (batch={batch_size}, heads={num_kv_heads}, seq={seq_len}, head_dim={gqa.head_dim}) [before repeat]")
print()
print("After repeat_interleave (to match Q heads):")
print(f" K shape: (batch={batch_size}, heads={num_query_heads}, seq={seq_len}, head_dim={gqa.head_dim})")
print(f" V shape: (batch={batch_size}, heads={num_query_heads}, seq={seq_len}, head_dim={gqa.head_dim})")
print()
print(f"Output shape: {gqa_output.shape}")
print()
# Calculate KV cache size for GQA
kv_cache_gqa = num_kv_heads * gqa.head_dim * seq_len * 2 # *2 for K and V
print(f"KV cache size per sample: {kv_cache_gqa:,} elements")
print()
# ============================================================================
# Comparison
# ============================================================================
print("=" * 70)
print("COMPARISON")
print("=" * 70)
print(f"MHA KV cache: {kv_cache_mha:,} elements")
print(f"GQA KV cache: {kv_cache_gqa:,} elements")
print(f"Memory reduction: {kv_cache_mha / kv_cache_gqa:.1f}x")
print()
print(f"MHA output shape: {mha_output.shape}")
print(f"GQA output shape: {gqa_output.shape}")
print()
print("✓ Both produce the same output shape!")
print()
# ============================================================================
# Visualizing the grouping
# ============================================================================
print("=" * 70)
print("QUERY HEAD GROUPING IN GQA")
print("=" * 70)
print(f"With {num_query_heads} query heads and {num_kv_heads} KV heads:")
print()
for kv_head in range(num_kv_heads):
start_q = kv_head * gqa.num_queries_per_kv
end_q = start_q + gqa.num_queries_per_kv - 1
print(f" KV head {kv_head} is shared by query heads {start_q}-{end_q}")
print()
print("=" * 70)
Results
| Method | Output shape | KV cache per sample |
|---|---|---|
| Multi-Head Attention | [2, 10, 512] | 10,240 elements |
| Grouped-Query Attention | [2, 10, 512] | 2,560 elements |
Both produce identical output dimensions, so GQA is a drop-in replacement for MHA — but its KV cache is 4× smaller, exactly matching the 4× reduction in KV heads (8 instead of 32). That ratio holds as you scale: longer sequences and more layers multiply the same 4× saving.
Memory Comparison Across Methods
| Method | Query Heads | KV Heads | KV Cache |
|---|---|---|---|
| Multi-Head Attention | 32 | 32 | 100% |
| Grouped-Query Attention | 32 | 8 | 25% |
| Multi-Query Attention | 32 | 1 | ~3.1% |
Why Modern LLMs Use GQA
Serving an LLM is a constant balance of quality, latency, and memory:
- MHA gives the most flexibility but the largest KV cache.
- MQA minimizes memory but sacrifices expressiveness by collapsing K/V to a single pair.
- GQA keeps most of MHA's modeling power while cutting the cache several-fold.
That balance is why GQA is the default in many recent model families — it makes long-context inference and large batch sizes practical on the same hardware.
Conclusion
Grouped-Query Attention is not a new attention mechanism so much as an inference optimization of Multi-Head Attention. By keeping many Query heads while sharing Keys and Values in groups, it dramatically reduces KV-cache memory and improves throughput with little quality cost.
As context windows keep growing, GQA has become one of the quiet architectural choices that lets modern LLMs serve long-context workloads efficiently.