Speculative Decoding
Autoregressive generation is slow for one structural reason: a large language model produces tokens one at a time, and every token requires a full forward pass through the entire model. Each pass is expensive, and they cannot be parallelized because each token depends on the one before it.
Speculative decoding breaks this bottleneck. A small, fast draft model guesses several tokens ahead, and the large target model checks all of those guesses in a single forward pass — accepting the ones it agrees with and correcting the first one it doesn't. Because one expensive pass now confirms multiple tokens instead of producing just one, generation gets faster. Crucially, the technique is exact: the final text follows the same probability distribution the target model would have produced on its own. Speed goes up; output quality does not change.
How It Works
Speculative decoding runs two models side by side: a small draft model and the full target model.
- Prime both models. The prompt is fed through both models to build their initial KV caches.
- Draft. The draft model — far smaller and faster than the target — proposes several future tokens at once instead of one. A typical setup speculates four tokens per step.
- Verify in parallel. The drafted tokens are appended to the sequence and passed to the target model. Because a transformer processes all positions in a single forward pass, the target model scores every drafted token simultaneously, which is what makes verification cheap relative to generating the tokens one by one.
- Accept what matches. Working left to right, the target model accepts each drafted token that passes its acceptance test and appends it to the output.
- Correct the first miss. When a drafted token is rejected, it and every token after it are thrown away — each guess depends on the ones before it, so nothing downstream can be trusted. The target model emits the correct token itself, and the cycle restarts from the new, longer sequence.
Every round guarantees forward progress: at minimum the one token the target model produces on a rejection, and often several more from accepted drafts. By collapsing what would have been many sequential passes into a single verification pass, speculative decoding raises throughput and cuts latency without altering the result.

How Tokens Are Verified
The acceptance test is what keeps the output mathematically identical to ordinary decoding.
For each drafted token, let q be the probability the draft model assigned it and p the probability the target model assigns it. The token is accepted with probability:
min(1, p / q)
In other words, a token the target model likes at least as much as the draft model (p ≥ q) is always accepted, while one the target model likes less is accepted only some of the time. When a token is rejected, the target model resamples from the corrected distribution (p − q) (normalized over positive values) rather than simply taking its top choice. This adjustment is the key detail: it provably makes the whole procedure equivalent to sampling directly from the target model. For greedy decoding the rule collapses to something simpler — accept the drafted token if it is the token the target model would itself have chosen.
As before, once a token is rejected, every later drafted token is discarded, since each one was conditioned on a prefix that has now changed.

Performance
The speedup is most visible side by side. The animation below contrasts generation with speculative decoding on versus off:
How much faster it runs depends on the acceptance rate — how often the draft model's guesses survive verification. A draft model that closely tracks the target accepts more tokens per round and delivers a larger speedup; a poorly aligned draft model wastes passes on rejected guesses. This single quantity is what most of the architectures below are designed to improve.
Alternative Architectures
Running a separate draft model is only one way to generate speculative tokens, and it carries a real cost: memory. The draft model is an entire second network that must stay resident in GPU memory next to the target and run its own forward pass on every decoding step.
Classic speculative decoding
70B target
+ 8B draft
-----------
78B parameters
You pay for both models in GPU memory and execute two transformers every iteration. The alternative is to attach lightweight prediction heads directly to the target model — adding only a small fraction of extra parameters instead of a whole second network. The two best-known designs are Medusa and EAGLE.
Medusa
Medusa eliminates the draft model entirely. It adds several lightweight prediction heads on top of the existing transformer, and each head predicts a future token directly from the model's final hidden state. The target model then verifies all of these guesses in a single forward pass.
Because the heads are tiny MLPs rather than a full model, the memory overhead is negligible:
70B transformer
+ tiny MLP heads
-----------------
≈ 70B parameters
That yields several advantages over the classic two-model setup:
- ✅ No second model to load
- ✅ Much lower GPU memory
- ✅ No two models to keep synchronized
- ✅ Less memory-bandwidth pressure

EAGLE
EAGLE also avoids a second transformer, but it drafts at the level of hidden states rather than tokens. A lightweight predictor takes the transformer's hidden state, predicts future hidden states, and the model's existing LM head converts those into tokens.
As with Medusa, only a lightweight module is added, so the footprint stays close to the base model:
70B transformer
+ tiny predictor
-----------------
≈ 70B parameters
Because hidden states carry richer context than discrete tokens, EAGLE's drafts align more closely with the target model — which raises the acceptance rate and, in turn, the speedup.

Comparison
| Feature | Classic | Medusa | EAGLE |
|---|---|---|---|
| Extra training | ❌ No | ✅ Yes | ✅ Yes |
| Second transformer | ✅ Yes | ❌ No | ❌ No |
| Extra GPU memory | High | Very low | Very low |
| Tiny MLP / predictor | ❌ No | ✅ Yes | ✅ Yes |
| Predicts | Tokens (small model) | Tokens | Hidden states |
| Acceptance rate | Good | Better | Often best |
Multi-Stage Speculator Heads
Medusa's heads each predict their token independently, which limits how coherent a multi-token draft can be. A stronger design arranges the heads hierarchically across stages: each stage predicts exactly one token and passes it to the next, forming a short sequential pipeline rather than a set of parallel guesses. Conditioning each prediction on the previous one yields more coherent drafts and higher acceptance rates.
In practice, trained speculative heads like these tend to give better latency improvements than a separate draft model while preserving output quality.

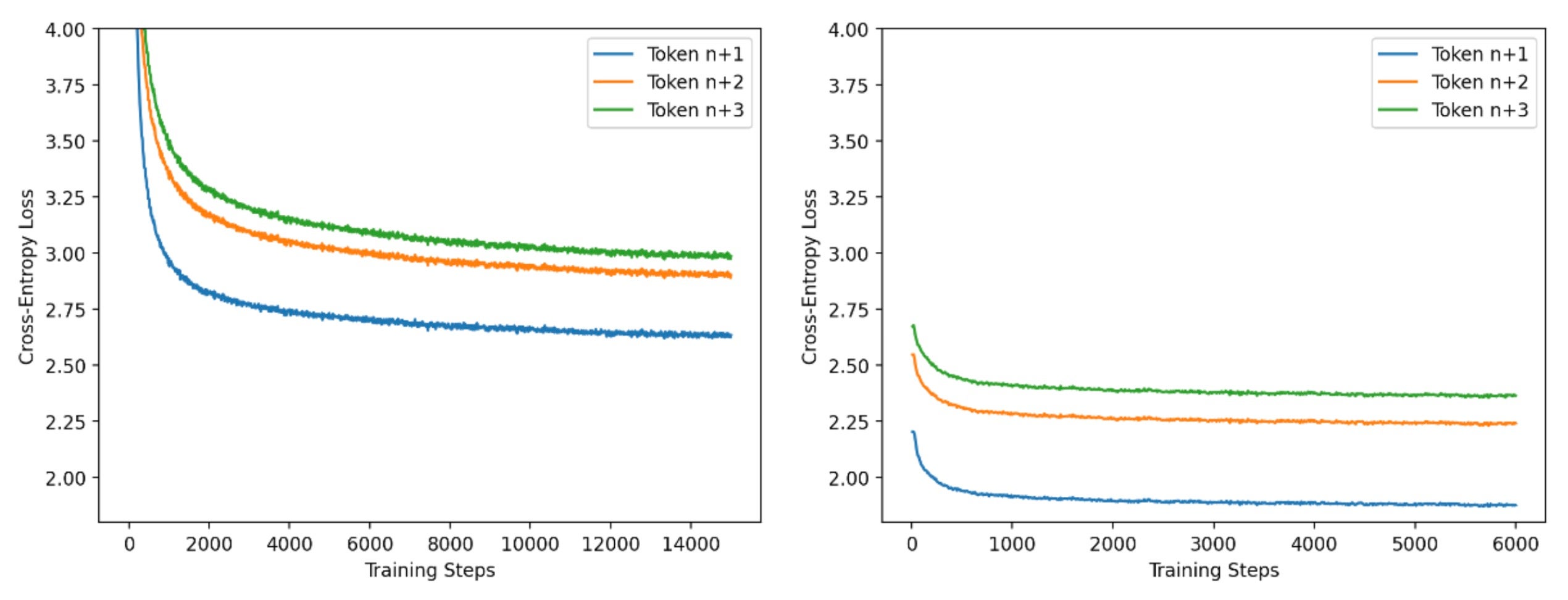
Training the Speculator
Speculative heads are trained in two phases.
Phase 1 — learn language. Train with small batches and long sequences (around 4K tokens) using the standard causal language modeling objective. This teaches the heads general next-token behavior.
Phase 2 — match the base model. Train with large batches and short sequences (around 256 tokens) drawn from the base model's own outputs, optimizing the heads to imitate the target model as closely as possible. The closer this imitation, the higher the acceptance rate at inference time.
Empirically, a 5:2 ratio of Phase 1 to Phase 2 steps works well. The figure below shows the training loss across both phases: