vLLM
What is vLLM?
vLLM is a high-performance inference engine designed for serving Large Language Models (LLMs). It is optimized to maximize GPU utilization and memory efficiency, enabling significantly higher throughput than traditional inference frameworks such as Hugging Face Transformers.
Unlike conventional serving systems that allocate memory contiguously for each request, vLLM introduces several innovations that allow many requests to share GPU memory efficiently while supporting advanced decoding strategies such as beam search and parallel sampling.
Benefits of vLLM
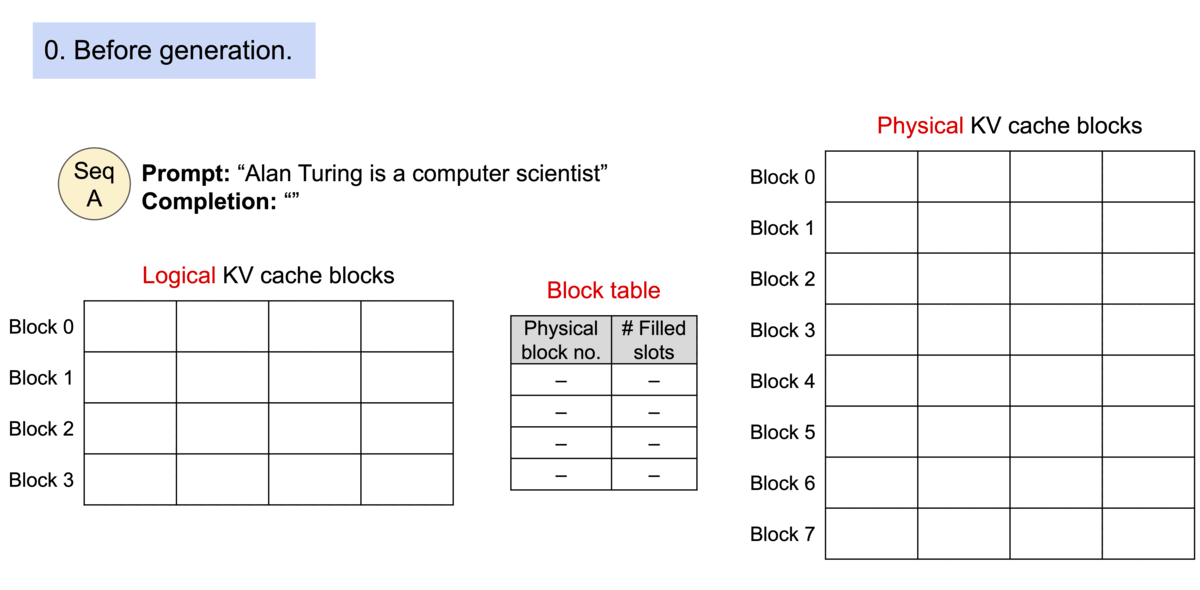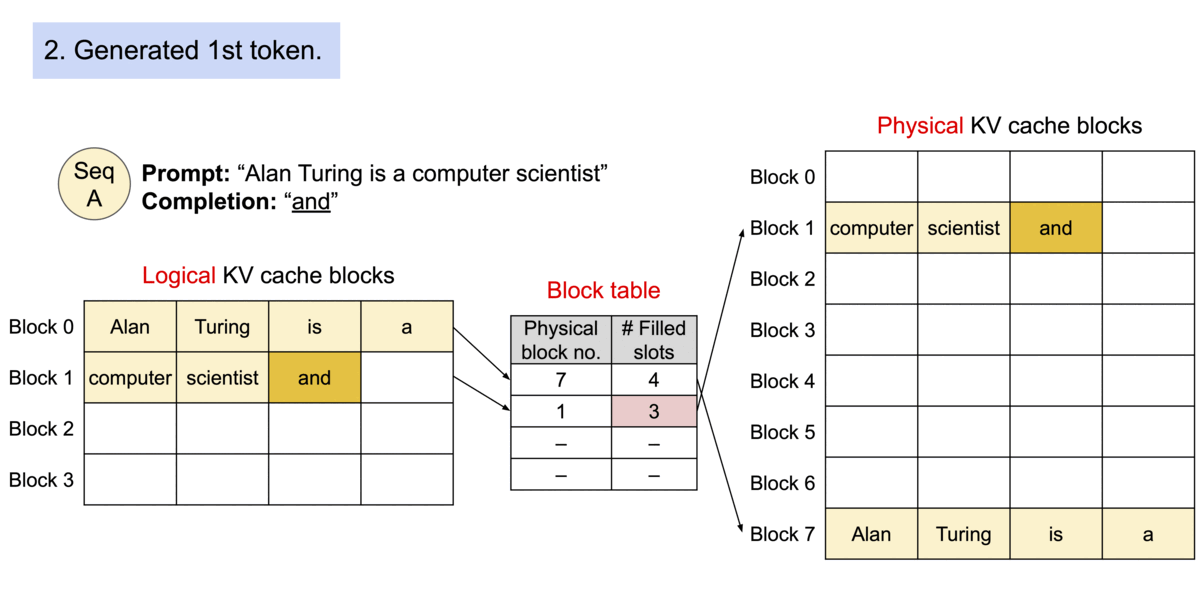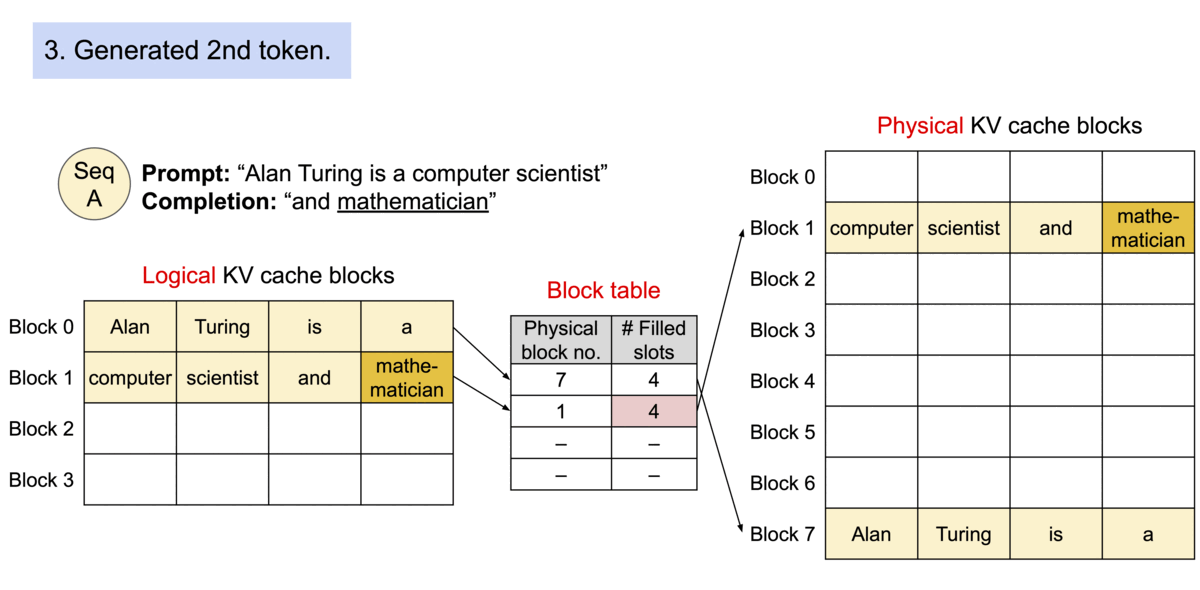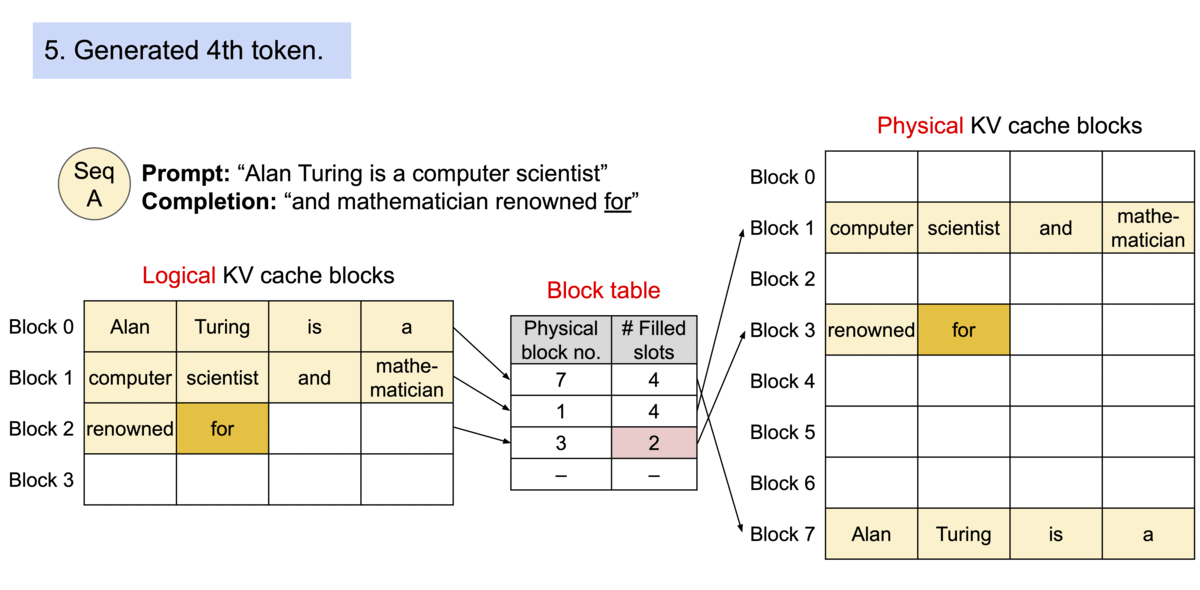
1. PagedAttention (Efficient KV Cache Management)
One of the biggest bottlenecks during LLM inference is storing the Key and Value (KV) cache generated during decoding.
Traditional implementations allocate contiguous memory for each sequence, leading to fragmentation and wasted GPU memory when sequences have different lengths.
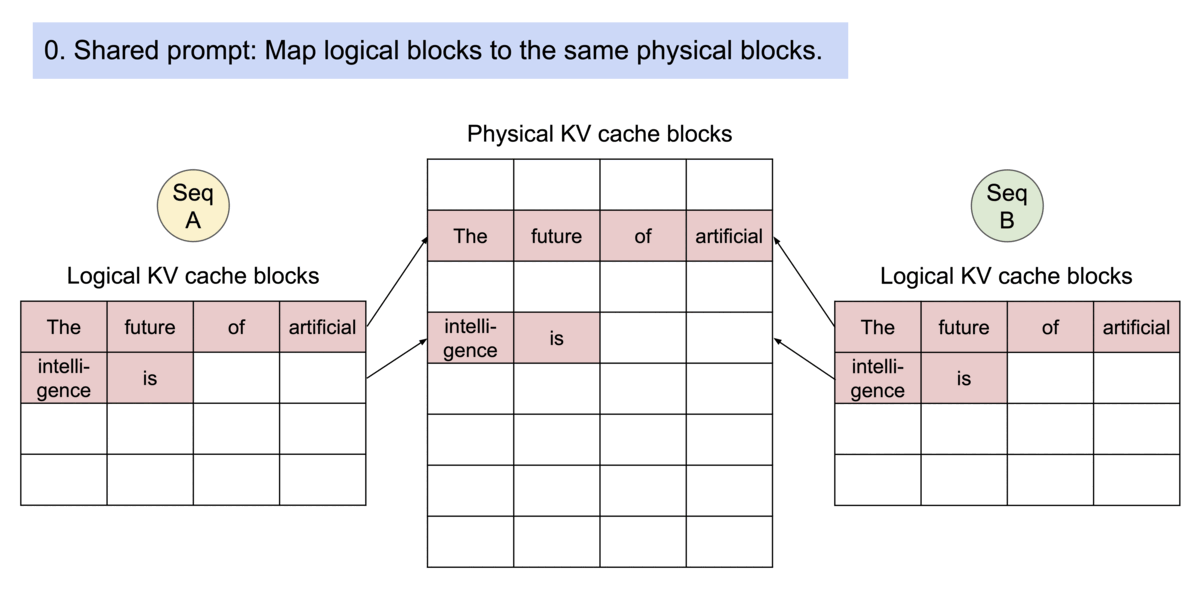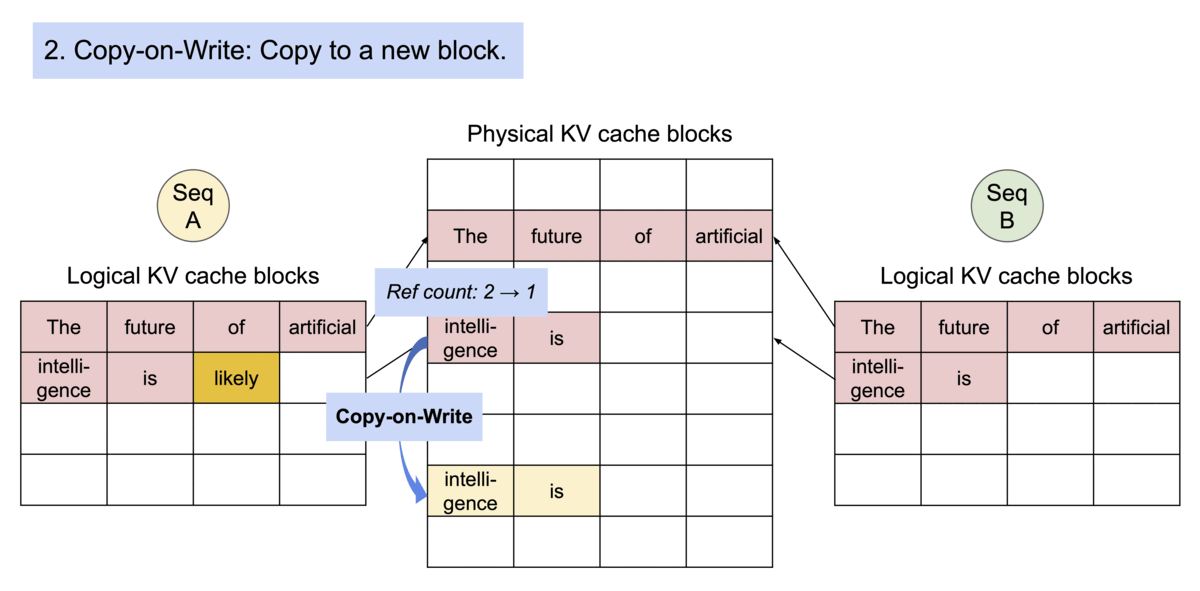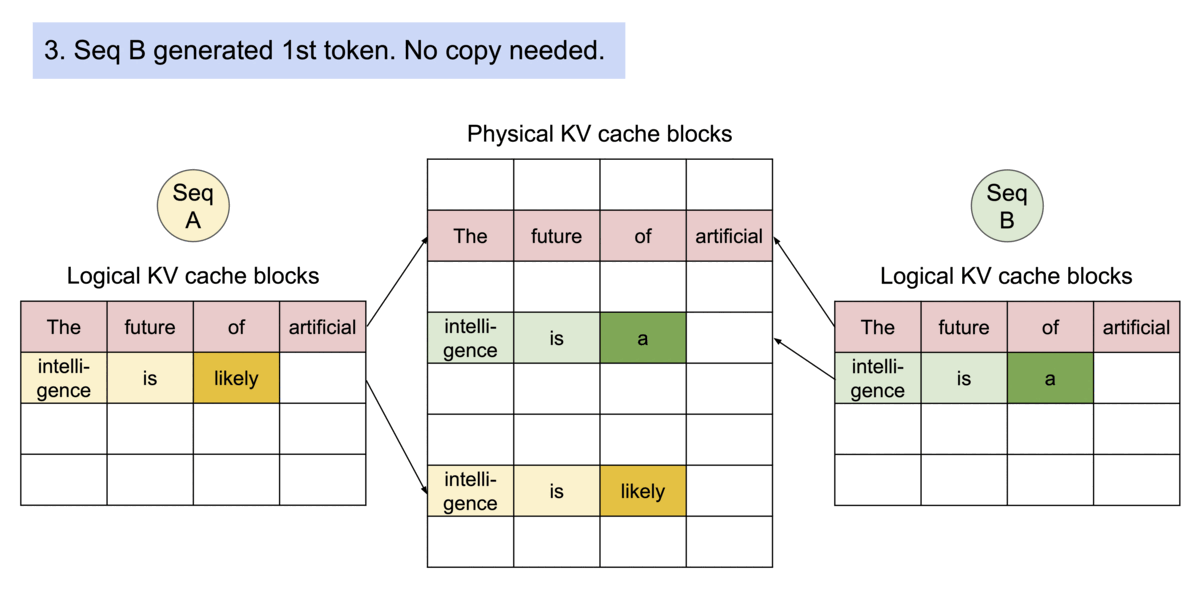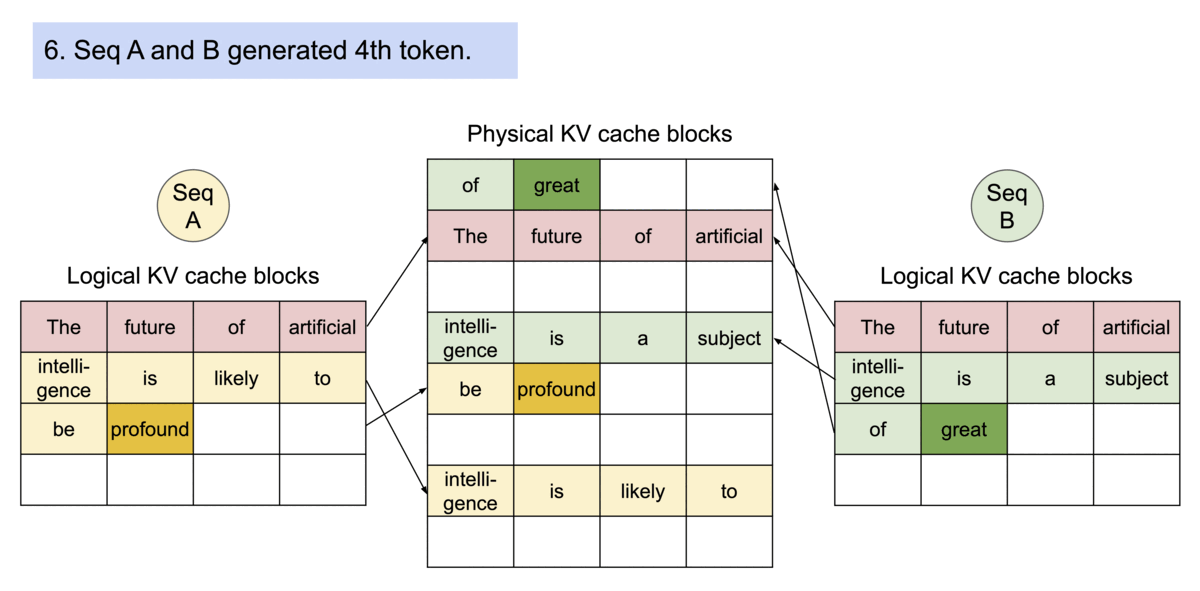
PagedAttention solves this problem by dividing the KV cache into fixed-size blocks. Each sequence maintains a logical block table that maps to physical memory blocks, similar to how operating systems manage virtual memory.
As tokens are generated, new blocks are allocated only when necessary, greatly reducing memory fragmentation and allowing many more concurrent requests to fit into GPU memory.
2. Beam Search and Parallel Sampling
vLLM efficiently supports beam search and parallel sampling by allowing multiple generated sequences to share the same KV cache blocks for their common prefix.
Instead of duplicating the entire KV cache for every candidate sequence, vLLM shares identical blocks until the outputs diverge. This significantly reduces memory usage while enabling multiple candidate responses to be generated simultaneously.
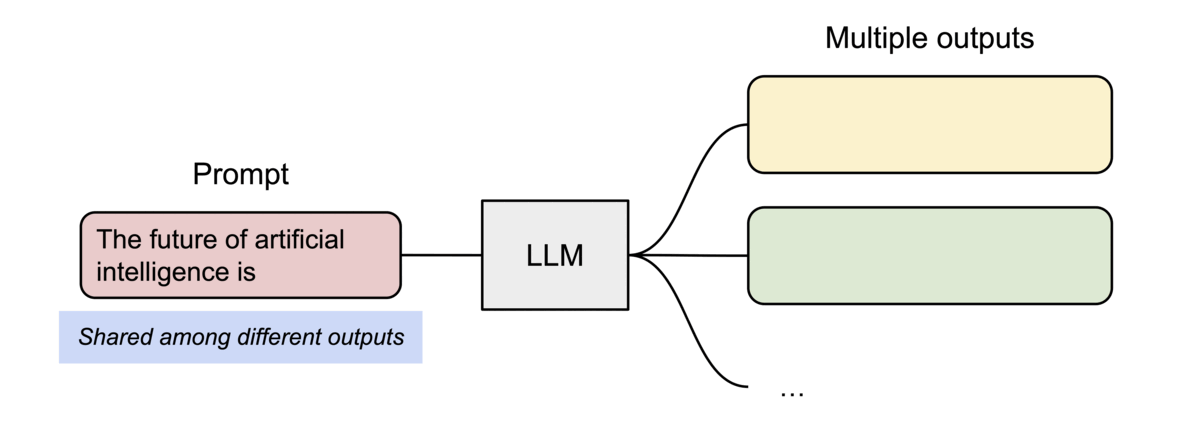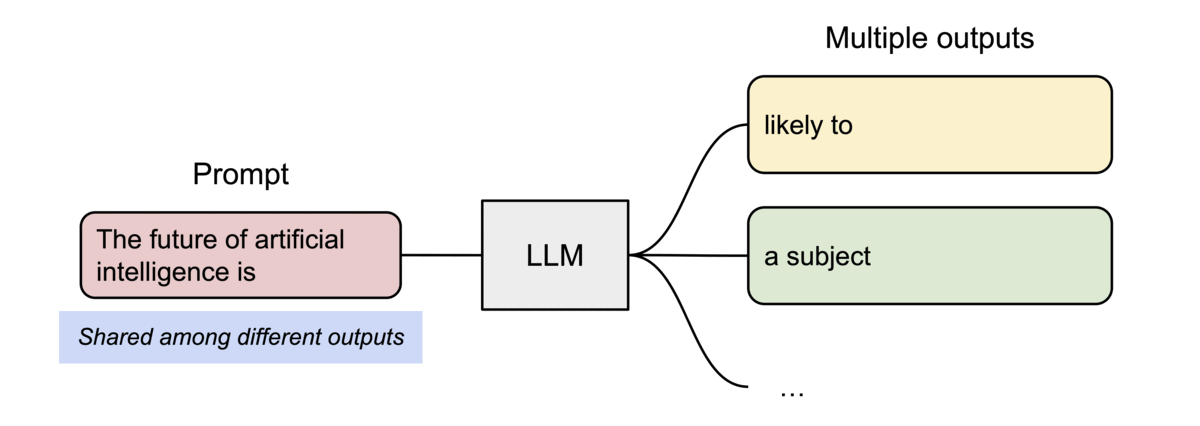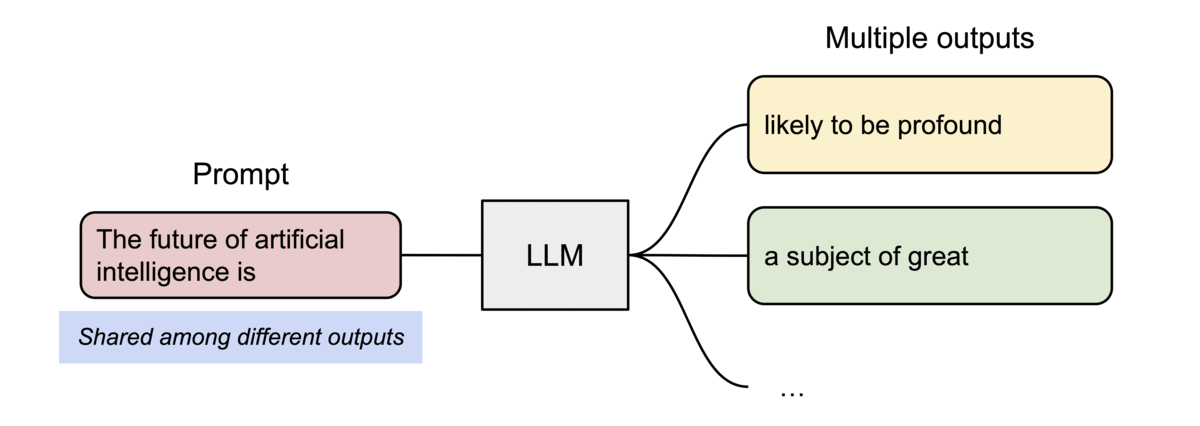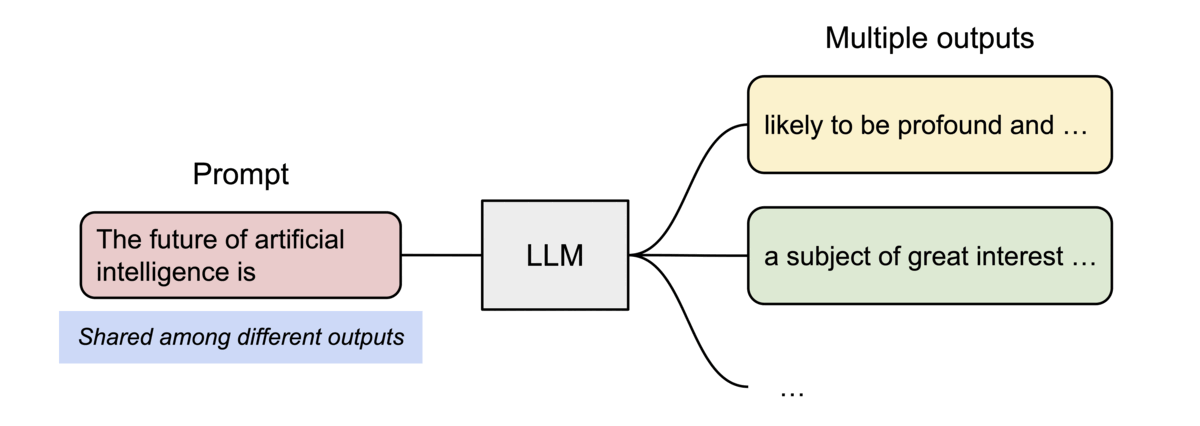
When two candidate sequences begin with the same prompt, they initially reference the same physical KV cache blocks. Only after their generated tokens differ does vLLM allocate new blocks for each sequence using a copy-on-write strategy.
3. Memory Swapping
When GPU memory becomes full, vLLM can evict inactive KV cache blocks from GPU memory to CPU RAM instead of discarding them entirely.
If those blocks are needed again later, they can be transferred back to the GPU without recomputing all previous attention states.
This mechanism enables vLLM to serve longer contexts and larger numbers of concurrent requests than would otherwise fit into GPU memory.
Although CPU memory is much slower than GPU memory, swapping is often still faster than recomputing the entire KV cache from scratch.
Benchmark Results and Analysis
| Batch Size | vLLM IFT (sec) | Hugging Face IFT (sec) |
|---|---|---|
| 4 | 2.32 | 5.32 |
| 8 | 2.51 | 7.24 |
| 16 | 3.01 | 9.50 |
| 32 | 3.38 | 12.90 |
IFT = Inference Time
The following figure visualizes the inference time comparison across different batch sizes.
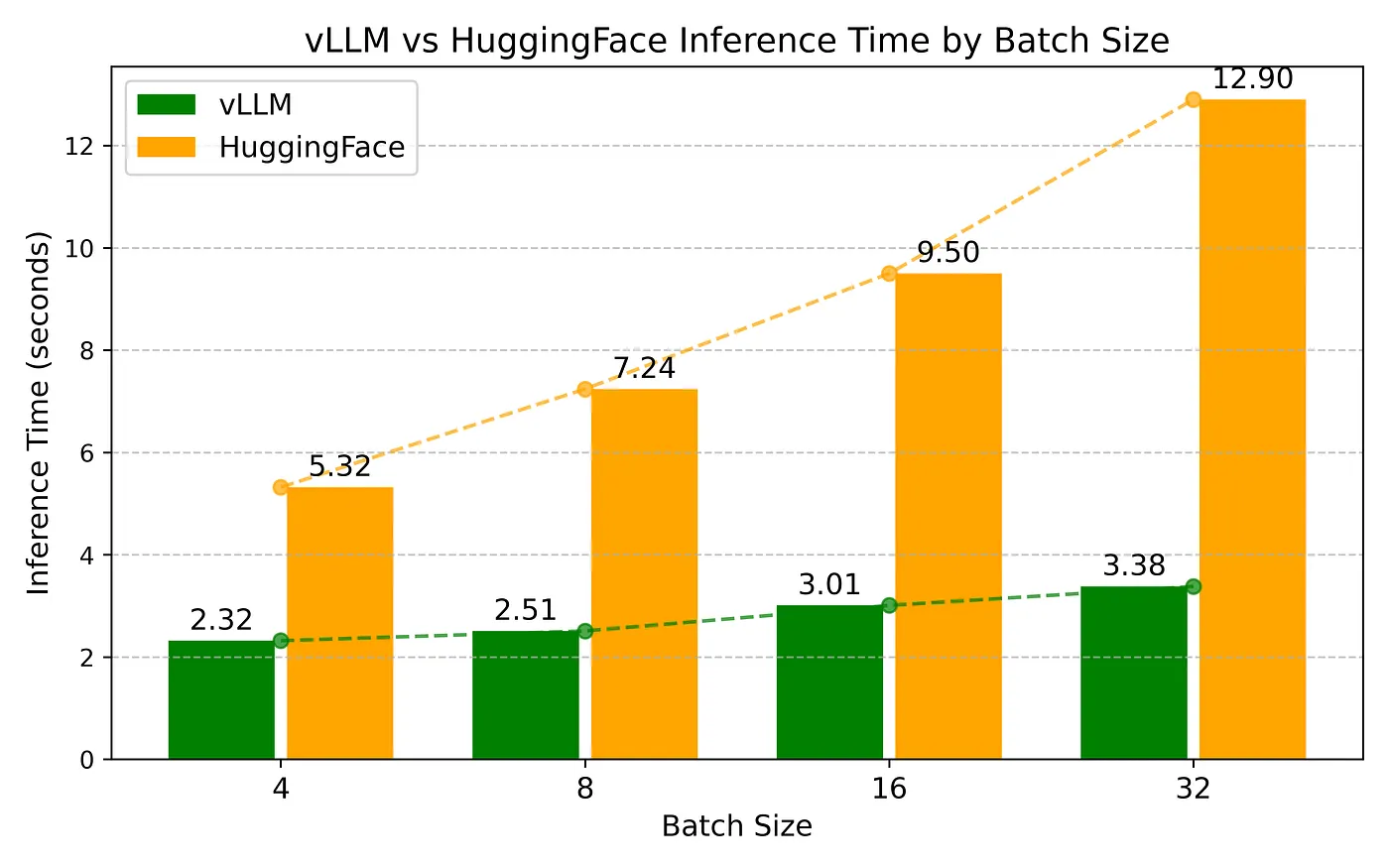
The benchmark demonstrates that vLLM substantially outperforms Hugging Face Transformers, particularly as the batch size increases.
Scalability
vLLM maintains relatively stable inference times even as the batch size grows. At a batch size of 32, vLLM completes inference in just 3.38 seconds, whereas Hugging Face requires 12.90 seconds.
This scalability is primarily enabled by PagedAttention, which minimizes memory fragmentation and allows efficient management of the KV cache.
GPU Utilization
vLLM employs continuous batching, allowing new requests to join an active batch while existing requests continue decoding.
Combined with optimized CUDA kernels, this approach minimizes GPU idle time and significantly improves throughput, resulting in better hardware utilization and lower serving costs.
Memory Efficiency
Traditional inference frameworks often allocate KV cache memory contiguously, which can lead to fragmentation and inefficient GPU memory usage.
By allocating memory in small fixed-size pages, vLLM reduces fragmentation and enables substantially more concurrent requests to fit within the same GPU memory budget.
GPU Memory Usage
The figure below illustrates the difference in GPU memory consumption between Hugging Face Transformers and vLLM.
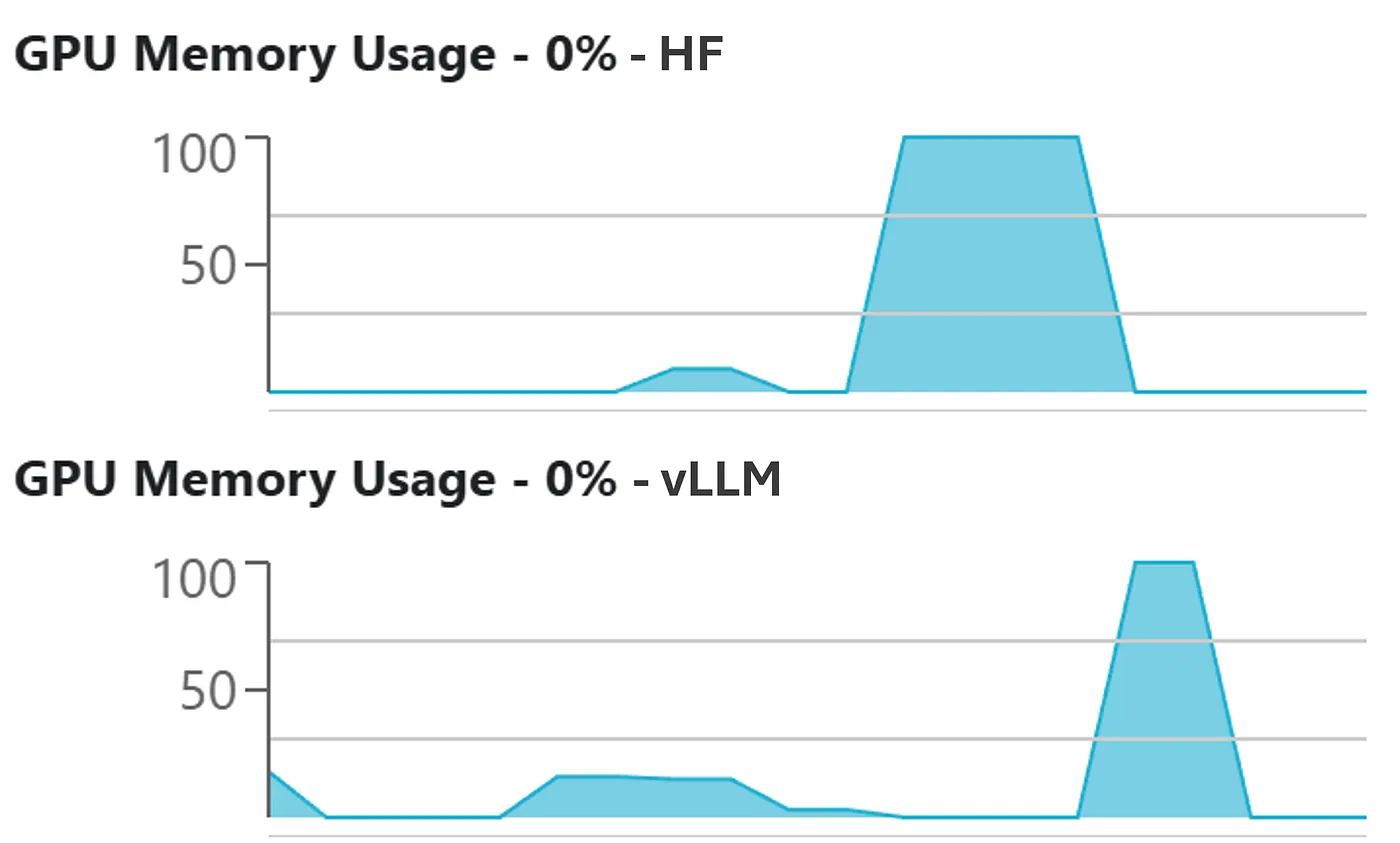
vLLM consistently uses GPU memory more efficiently because of its paged KV cache architecture and block-sharing mechanism, allowing it to serve larger workloads without exhausting available memory.
Throughput Benchmark
The following benchmark measures serving throughput when each request generates a single output completion.
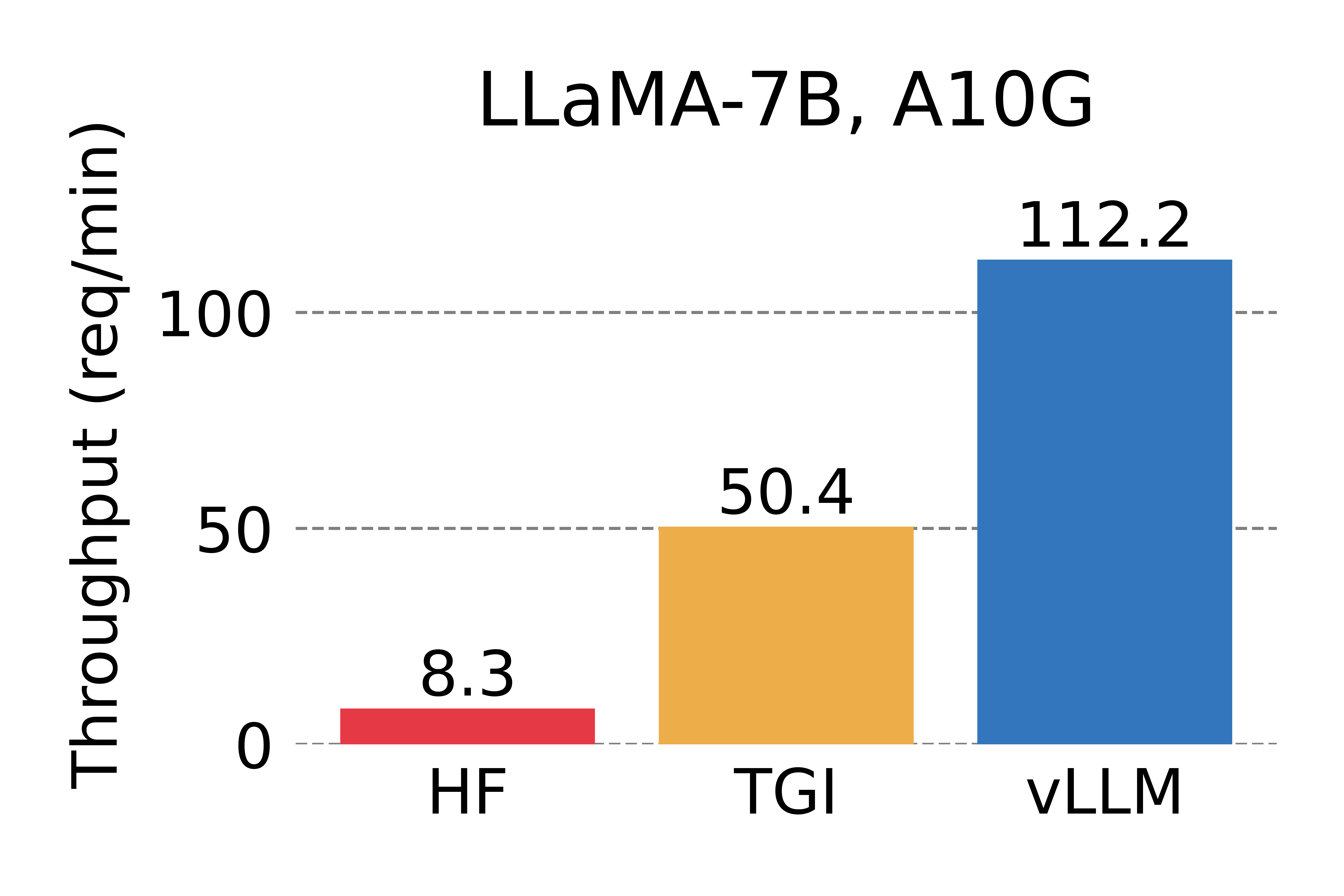
The results show that vLLM achieves approximately 14× to 24× higher throughput than Hugging Face Transformers and 2.2× to 2.5× higher throughput than Text Generation Inference (TGI).
These improvements stem from several complementary optimizations:
- PagedAttention for efficient KV cache allocation
- Continuous batching for higher GPU utilization
- Copy-on-write KV cache sharing for beam search and parallel sampling
- Memory swapping between GPU and CPU when necessary
Together, these techniques make vLLM one of the most efficient inference engines for deploying large language models at scale.
Conclusion
vLLM introduces a fundamentally different approach to LLM serving by treating the KV cache similarly to virtual memory in an operating system.
Its innovations, including PagedAttention, block sharing, copy-on-write, continuous batching, and memory swapping, dramatically improve throughput, reduce memory waste, and increase GPU utilization.
For production deployments that require serving many concurrent requests efficiently, vLLM offers substantial performance advantages over traditional inference frameworks while remaining compatible with a wide range of modern large language models.